Сайт i2ocr.com
Отзыв про Сайт i2ocr.com
Совсем недавно мне потребовалось распознать один свой старый текст, которого не было у меня в электронном виде. Был он только на бумаге. Информация же в цифровом формате требовалась срочно, а набор текста на компьютере занял бы много времени и я могла не успеть в срок. В этом частично помогло сканирование. Но вот программы для распознавания текста у меня не было и я решила попробовать поискать в сети онлайн сервисы, которые помогают распознать текст онлайн, бесплатно, и без ограничений.
Должна сказать, что это было и легко, и сложно. Почему? А потому, что на многих сайтах были ограничения на количество страниц, а на каких-то не было возможности распознать русский текст - только английский.
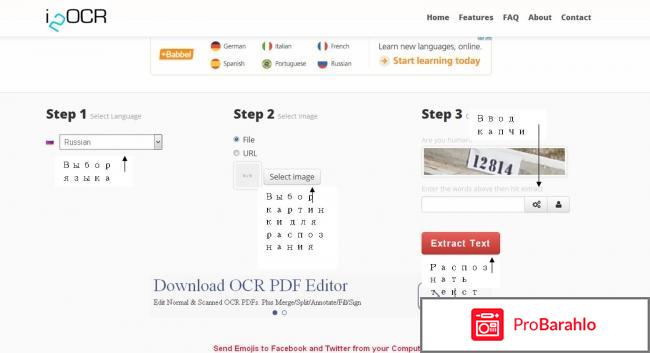
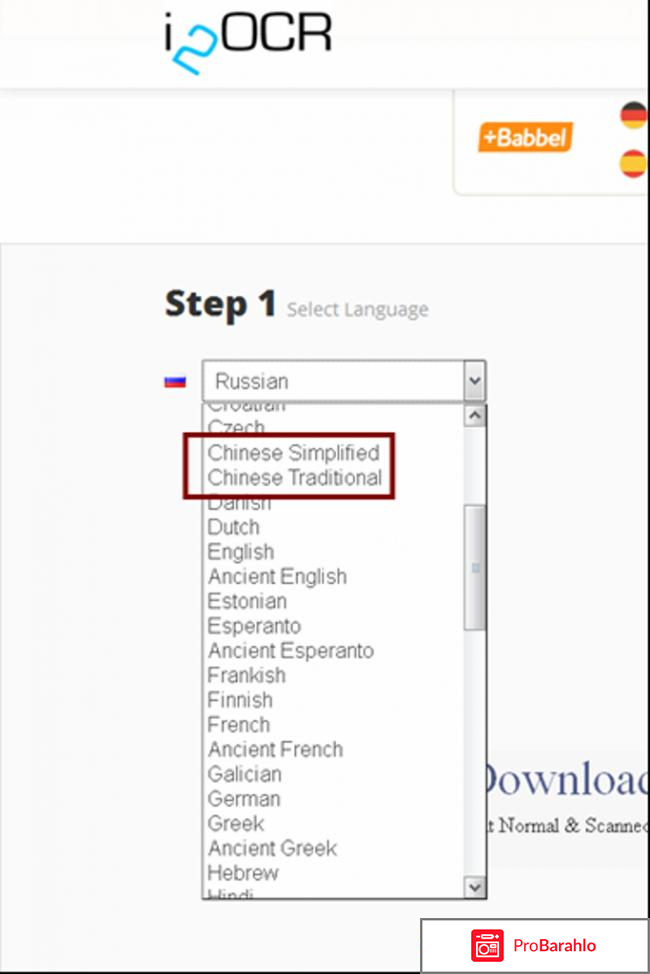
И вот искала я, искала и нашла i2ocr. Порадовало, что ограничений там нет, как на других сайтах. Документ был объёмный и я смогла распознать здесь все страницы. Понятное дело, что есть возможность распознавать тексты на русском языке. Вообще, выбор языков огромный. Есть даже китайский (как упрощённые, так и традиционные иероглифы). Так что, если вам нужно распознать онлайн иероглифы, то это один из немногих сайтов, где это можно сделать.
 После распознавания текст можно скачать в нескольких форматах - .txt, .doc, pdf.
После распознавания текст можно скачать в нескольких форматах - .txt, .doc, pdf.
Теперь о минусах. Если есть картинка, то её система не учитывает. Если текст в оригинале сделан колонками, то на выходе он будет сплошным, при этом, колонки не смешиваются, то есть, путаницы нет (это плюс). То есть, форматировать текст потом придётся самостоятельно, равно как и вставлять изображения. То же самое касается таблиц и схем. Правда, слова из таблиц распознаются.
Нужно вводить капчу. Несмотря на то, что есть русский язык для распознавания, интерфейс весь на английском.
Нет возможности редактировать текст онлайн. По крайней мере, я её не обнаружила. Приходится как-то изворачиваться, чтобы сверить получившийся результат.
Если лист при сканировании был неровно положен или же есть загибы (в книгах, ближе к середине), то есть вероятность, что текст распознается плохо на этих местах. Так что лучше выровнять изображение.
Далее. Если текст колонками, то я бы рекомендовала распознавать каждую колонку отдельно. При этом, если лист сероватый (особенно это видно при фотографировании), то лучше сделать так, чтобы он был белым.
В общем, лучше сканировать, чем фотографировать. Текст должен быть ровным, буквы чёткими. В этом случае распознанный результат практически не нуждается в редактировании и сверка происходит очень быстро. Как только я это поняла, то все проблемы снялись.
Сервис рекомендую.
-
Веб-мастеруВеб-мастеру(43)
-
Интернет-магазиныИнтернет-магазины(4222)
-
Онлайн-сервисыОнлайн-сервисы(3102)
-
Разное (сайты)Разное (сайты)(4870)